











 AI智能应用开发
AI智能应用开发 AI大模型开发(Python)
AI大模型开发(Python) AI鸿蒙开发
AI鸿蒙开发 AI嵌入式+机器人开发
AI嵌入式+机器人开发 AI运维
AI运维 AI测试
AI测试 跨境电商运营
跨境电商运营 AI设计
AI设计 AI视频创作与直播运营
AI视频创作与直播运营 微短剧拍摄剪辑
微短剧拍摄剪辑 C/C++
C/C++ 狂野架构师
狂野架构师


HDFS存储架构中主从节点关系?工作原理是什么?
更新时间:2020年12月30日11时44分 来源:传智教育 浏览次数:

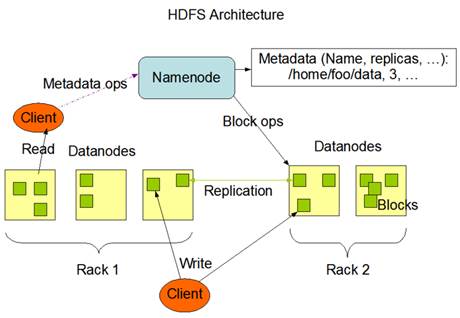
图1 HDFS存储架构图
从图1可以看出,HDFS采用主从架构(Master/Slave架构)。HDFS集群分别是由一个NameNode和多个的 DataNode组成。其中,NameNode是HDFS集群的主节点,负责管理文件系统的命名空间以及客户端对文件的访问;DataNode是集群的从节点,负责管理它所在节点上的数据存储。HDFS分布式文件系统中的NameNode和DataNode两种角色各司其职,共同协调完成分布式的文件存储服务。
那么,NameNode是如何管理分布式文件系统的命名空间呢?其实,在NameNode内部是以元数据的形式,维护着两个文件,分别是FsImage镜像文件和EditLog日志文件。其中,FsImage镜像文件用于存储整个文件系统命名空间的信息,EditLog日志文件用于持久化记录文件系统元数据发生的变化。当NameNode启动的时候,FsImage镜像文件就会被加载到内存中,然后对内存里的数据执行记录的操作,以确保内存所保留的数据处于最新的状态,这样就加快了元数据的读取和更新操作。
随着集群运行时间长,NameNode中存储的元数据信息越来越多,这样就会导致EditLog日志文件越来越大。当集群重启时,NameNode需要恢复元数据信息,首先加载上一次的FsImage镜像文件,然后在重复EditLog日志文件的操作记录,一旦EditLog日志文件很大,在合并的过程中就会花费很长时间,而且如果NameNode宕机就会丢失数据。为了解决这个问题,HDFS中提供了Secondary NameNode(辅助名称节点),它并不是要取代掉NameNode也不是NameNode的备份, 它的职责主要是是周期性的把NameNode中的EditLog日志文件合并到FsImage镜像文件中,从而减小EditLog日志文件的大小,缩短集群重启时间,并且也保证了HDFS系统的完整性。
Namenode存储的是元数据信息,元数据信息并不是真正的数据,真正的数据是存储在DataNode中。DataNode是负责管理它所在节点上的数据存储。DataNode中的数据块是以文件的类型存储在磁盘中,其中包含两个文件,一是数据本身(仅数据),二是每个数据块对应的一个元数据文件(包括数据长度,块数据校验和,以及时间戳)。
猜你喜欢:
最新资讯




















江苏传智播客教育科技股份有限公司 版权所有Copyright 2006-2024 All
Rights Reserved
苏ICP备16007882号营业执照增值电信业务经营许可证出版物经营许可证 苏公网安备 32132202001156号
苏公网安备 32132202001156号
免费领取黑马程序员AI通道专属星级课程资料
