











 AI智能应用开发
AI智能应用开发 AI大模型开发(Python)
AI大模型开发(Python) AI鸿蒙开发
AI鸿蒙开发 AI嵌入式+机器人开发
AI嵌入式+机器人开发 AI运维
AI运维 AI测试
AI测试 跨境电商运营
跨境电商运营 AI设计
AI设计 AI视频创作与直播运营
AI视频创作与直播运营 微短剧拍摄剪辑
微短剧拍摄剪辑 C/C++
C/C++ 狂野架构师
狂野架构师


RDD为什么要进行数据持久化?持久化操作步骤
更新时间:2020年12月22日16时49分 来源:传智教育 浏览次数:

在Spark中,RDD是采用惰性求值,即每次调用行动算子操作,都会从头开始计算。然而,每次调用行动算子操作,都会触发一次从头开始的计算,这对于迭代计算来说,代价是很大的,因为迭代计算经常需要多次重复的使用同一组数据集,所以,为了避免重复计算的开销,可以让Spark对数据集进行持久化。
通常情况下,一个RDD是由多个分区组成的,RDD中的数据分布在多个节点中,因此,当持久化某个RDD时,每一个节点都将把计算分区的结果保存在内存中,若对该RDD或衍生出的RDD进行其他行动算子操作时,则不需要重新计算,直接去取各个分区保存数据即可,这使得后续的行动算子操作速度更快(通常超过10倍),并且缓存是Spark构建迭代式算法和快速交互式查询的关键。
RDD的持久化操作有两种方法,分别是cache()方法和persist()方法。每一个持久化的RDD都可以使用不同的存储级别存储,从而允许持久化数据集在硬盘或者内存作为序列化的Java对象,甚至可以跨节点复制。
persist()方法的存储级别是通过StorageLevel对象(Scala、Java、Python)设置的。
cache()方法的存储级别是使用默认的存储级别(即StorageLevel.MEMORY_ONLY(将反序列化的对象存入内存))。接下来,通过一张表介绍一下持久化RDD的存储级别,如表1所示。
表1 持久化RDD的存储级别
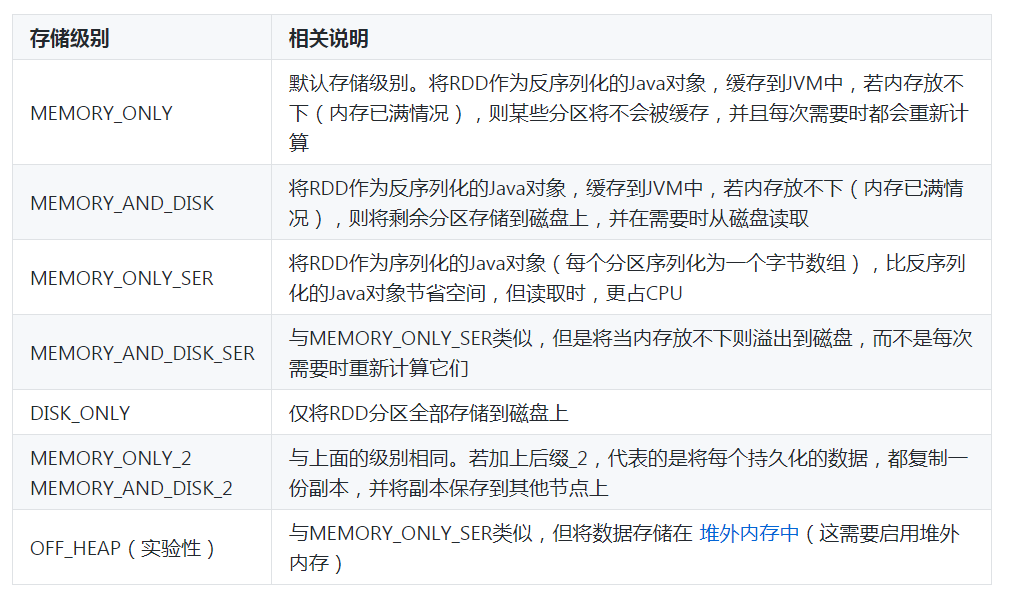
在表1中,列举了持久化RDD的存储级别,我们可以在RDD进行第一次算子操作时,根据自己的需求选择对应的存储级别。
为了大家更好地理解,接下来,通过代码演示如何使用persist()方法和cache()方法对RDD进行持久化。
1.使用persist()方法对RDD进行持久化
定义一个列表list,通过该列表创建一个RDD,然后通过persist持久化操作和算子操作统计RDD中的元素个数以及打印输出RDD中的所有元素。具体代码如下:
scala> import org.apache.spark.storage.StorageLevel
import org.apache.spark.storage.StorageLevel
scala> val list = List("hadoop","spark","hive")
list: List[String] = List(hadoop, spark, hive)
scala> val listRDD = sc.parallelize(list)
listRDD: org.apache.spark.rdd.RDD[String] = ParallelCollectionRDD[0] at
parallelize at :27
scala> listRDD.persist(StorageLevel.DISK_ONLY)
res1: listRDD.type = ParallelCollectionRDD[0] at parallelize at :27
scala> println(listRDD.count())
3
scala> println(listRDD.collect().mkString(","))
hadoop,spark,hive
上述代码中,第1行代码导入StorageLevel对象的包;第3行代码定义了一个列表list;第5行代码执行sc.parallelize(list)操作,创建了一个RDD,即listRDD;第8行代码添加了persist()方法,用于持久化RDD,减少I/O操作,提高计算效率;第10行代码执行listRDD.count()行动算子操作,将统计listRDD中元素的个数;第12行代码执行listRDD.collect()行动算子操作和mkString(“,”)操作,将listRDD中的所有元素进行打印输出,并且是以逗号为分隔符。
需要注意的是,当程序执行到第8行代码时,并不会持久化listRDD,因为listRDD还没有被真正计算;当执行第10行代码时,listRDD才会进行第一次的行动算子操作,触发真正的从头到尾的计算,这时listRDD.persist()方法才会被真正的执行,把listRDD持久化到磁盘中;当执行到第12行代码时,进行第二次的行动算子操作,但不触发从头到尾的计算,只需使用已经进行持久化的listRDD来进行计算。
2.使用cache()方法对RDD进行持久化
定义一个列表list,通过该列表创建一个RDD,然后通过cache持久化操作和算子操作统计RDD中的元素个数以及打印输出rdd中的所有元素。具体代码如下:
scala> val list= List("hadoop","spark","hive")
list: List[String] = List(hadoop, spark, hive)
scala> val listRDD= sc.parallelize(list)
listRDD: org.apache.spark.rdd.RDD[String] = ParallelCollectionRDD[0] at
parallelize at :26
scala> listRDD.cache()
res2: listRDD.type = ParallelCollectionRDD[1] at parallelize at :26
scala> println(listRDD.count())
3
scala> println(listRDD.collect().mkString(","))
hadoop,spark,hive
上述代码中,第6行代码对listRDD进行持久化操作,即添加cache()方法,用于持久化RDD,减少I/O操作,提高计算效率。然而,使用cache()方法进行持久化操作,底层是调用了persist(MEMORY_ONLY)方法,用来对RDD进行持久化。当程序当执行到第6行代码时,并不会持久化listRDD,因为listRDD还没有被真正计算;当程序执行第8行代码时,listRDD才会进行第一次的行动算子操作,触发真正的从头到尾的计算,这时listRDD.cache()方法才会被真正的执行,把listRDD持久化到内存中;当程序执行到第10行代码时,进行第二次的行动算子操作,但不触发从头到尾的计算,只需使用已经持久化的listRDD来进行计算。
猜你喜欢:最新资讯




















江苏传智播客教育科技股份有限公司 版权所有Copyright 2006-2024 All
Rights Reserved
苏ICP备16007882号营业执照增值电信业务经营许可证出版物经营许可证 苏公网安备 32132202001156号
苏公网安备 32132202001156号
免费领取黑马程序员AI通道专属星级课程资料
