











 AI智能应用开发
AI智能应用开发 AI大模型开发(Python)
AI大模型开发(Python) AI鸿蒙开发
AI鸿蒙开发 AI嵌入式+机器人开发
AI嵌入式+机器人开发 AI运维
AI运维 AI测试
AI测试 跨境电商运营
跨境电商运营 AI设计
AI设计 AI视频创作与直播运营
AI视频创作与直播运营 微短剧拍摄剪辑
微短剧拍摄剪辑 C/C++
C/C++ 狂野架构师
狂野架构师


JVM内存模型详细介绍[java培训]
更新时间:2020年03月15日10时30分 来源:传智播客 浏览次数:
Web服务端是Java语言最擅长的领域之一,也会Java最广泛应用的地方。而高并发高吞吐量也越来越成为服务端普遍需求,所有能够开发出高效并发的应用程序,也是成为一个高级程序员的必备技能。下面我们将从JVM内存模型的角度来分析虚拟机如何实现多线程、多线程之间由于共享和竞争数据而导致的并发问题及解决思路。
计算机硬件内存架构
想要了解JVM内存模型,我们需要先了解下计算机的硬件内存架构
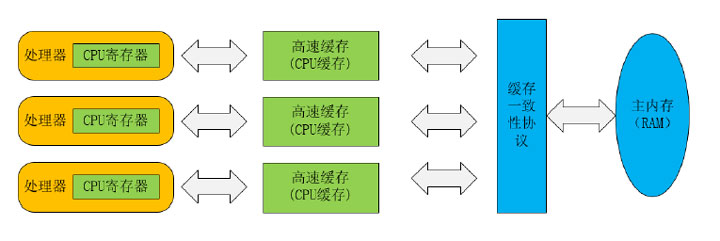
正如上图所示,经过简化CPU与内存操作的简易图,实际上没有这么简单,这里为了理解方便,我们省去了南北桥并将三级缓存统一为CPU缓存(有些CPU只有二级缓存,有些CPU有三级缓存)。就目前计算机而言,一般拥有多个CPU并且每个CPU可能存在多个核心,多核是指在一枚处理器(CPU)中集成两个或多个完整的计算引擎(内核),这样就可以支持多任务并行执行,从多线程的调度来说,每个线程都会映射到各个CPU核心中并行运行。在CPU内部有一组CPU寄存器,寄存器是CPU直接访问和处理的数据,是一个临时放数据的空间。一般CPU都会从内存取数据到寄存器,然后进行处理,但由于内存的处理速度远远低于CPU,导致CPU在处理指令时往往花费很多时间在等待内存做准备工作,于是在寄存器和主内存间添加了CPU缓存,CPU缓存比较小,但访问速度比主内存快得多,用它来作为内存与处理器之间的缓冲:将运算需要使用到的数据复制到缓存中,让运算能快速进行,当运算结束后再从缓存同步到内存之中,这样处理器就不用等待缓慢的内存读写了。
基于高速缓存的存储交互很好的解决了处理器与内存的速度矛盾,但也为计算机系统 带来了更高的复杂度,因为它引入了一个新的问题:缓存一致性。在多处理器系统中,每个处理器都有自己的高速缓存,而它们又共享同一主内存(RAM)。当多个处理器的运算任务都涉及同一块主内存区域时,将可能导致各自的缓存数据不一致,为了解决一致性问题,需要各个处理器访问缓存时都遵循一些协议,在读写时根据协议来进行操作,这些协议有MSI、MESI、MOSI等。被称为硬件的“内存模型”,可以理解为在特定的操作协议下,对特定的内存或高速缓存进行读写访问的过程抽象。不同架构的物理机器可以拥有不一样的内存模型,而我们的JAVA虚拟机也有自己的内存模型。
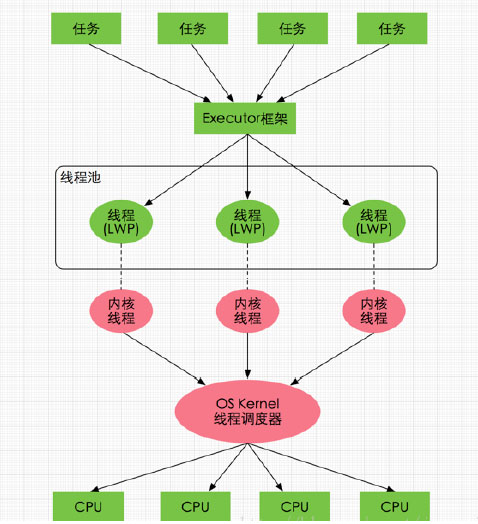
Java线程与硬件处理器
了解完硬件的内存架构后,接着了解JVM中线程的实现原理,理解线程的实现原理,有助于我们了解Java内存模型与硬件内存架构的关系,在Window系统和Linux系统上,Java线程的实现是基于一对一的线程模型,所谓的一对一模型,实际上就是通过语言级别层面程序去间接调用系统内核的线程模型,即我们在使用Java线程时,Java虚拟机内部是转而调用当前操作系统的内核线程来完成当前任务。这里需要了解一个术语,内核线程(Kernel-Level Thread,KLT),它是由操作系统内核(Kernel)支持的线程,这种线程是由操作系统内核来完成线程切换,内核通过操作调度器进而对线程执行调度,并将线程的任务映射到各个处理器上。每个内核线程可以视为内核的一个分身,这也就是操作系统可以同时处理多任务的原因。由于我们编写的多线程程序属于语言层面的,程序一般不会直接去调用内核线程,取而代之的是一种轻量级的进程(Light Weight Process),也是通常意义上的线程,由于每个轻量级进程都会映射到一个内核线程,因此我们可以通过轻量级进程调用内核线程,进而由操作系统内核将任务映射到各个处理器,这种轻量级进程与内核线程间1对1的关系就称为一对一的线程模型。
Java内存模型
内存模型概述
Java内存模型(即Java Memory Model,简称JMM)本身是一种抽象的概念,并不真实存在,它描述的是一组规则或规范,通过这组规范定义了程序中各个变量(包括实例字段,静态字段和构成数组对象的元素)的访问方式。
Java内存模型的主要目标是定义程序中的各个变量的访问规则,即如何在虚拟机中将变量存储到内存和从内存中取出。此处的变量不包括局部变量和方法参数,因为它们是线程私有的,不会被共享,自然不存在竞争问题。由于JVM运行程序的实体是线程,而每个线程创建时JVM都会为其创建一个工作内存(有些地方称为栈空间),用于存储线程私有的数据,而Java内存模型中规定所有变量都存储在主内存,主内存是共享内存区域,所有线程都可以访问,但线程对变量的操作(读取赋值等)必须在工作内存中进行,首先要将变量从主内存拷贝的自己的工作内存空间,然后对变量进行操作,操作完成后再将变量写回主内存,不能直接操作主内存中的变量,工作内存中存储着主内存中的变量副本拷贝,前面说过,工作内存是每个线程的私有数据区域,因此不同的线程间无法访问对方的工作内存,线程间的通信(传值)必须通过主内存来完成,线程、主内存、工作内存三者的关系如下图
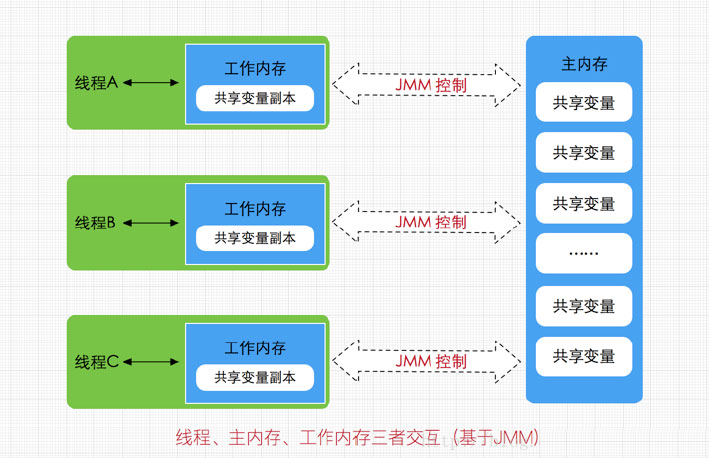
弄清楚主内存和工作内存后,接了解一下主内存与工作内存的数据存储类型以及操作方式,根据虚拟机规范,对于一个实例对象中的成员方法而言,如果方法中包含本地变量是基本数据类型(boolean,byte,short,char,int,long,float,double),将直接存储在工作内存的帧栈结构中,但倘若本地变量是引用类型,那么该变量的引用会存储在功能内存的帧栈中,而对象实例将存储在主内存(共享数据区域,堆)中。但对于实例对象的成员变量,不管它是基本数据类型或者包装类型(Integer、Double等)还是引用类型,都会被存储到堆区。至于static变量以及类本身相关信息将会存储在主内存中。需要注意的是,在主内存中的实例对象可以被多线程共享,倘若两个线程同时调用了同一个对象的同一个方法,那么两条线程会将要操作的数据拷贝一份到自己的工作内存中,执行完成操作后才刷新到主内存。
JAVA内存模型与JAVA内存区域关系
这里需要注意下JAVA内存模型中的主内存、工作内存与JAVA内存区域中的JAVA堆、栈、方法区不是同一层次的内存划分,不要混淆。
JAVA内存模型
·主内存
主要存储的是Java实例对象,所有线程创建的实例对象都存放在主内存中,不管该实例对象是成员变量还是方法中的本地变量(也称局部变量),当然也包括了共享的类信息、常量、静态变量。由于是共享数据区域,多条线程对同一个变量进行访问可能会发现线程安全问题。
·工作内存
主要存储当前方法的所有本地变量信息(工作内存中存储着主内存中的变量副本拷贝),每个线程只能访问自己的工作内存,即线程中的本地变量对其它线程是不可见的,就算是两个线程执行的是同一段代码,它们也会各自在自己的工作内存中创建属于当前线程的本地变量,当然也包括了字节码行号指示器、相关Native方法的信息。注意由于
工作内存是每个线程的私有数据,线程间无法相互访问工作内存,因此存储在工作内存的数据不存在线程安全问题。
Java内存区域
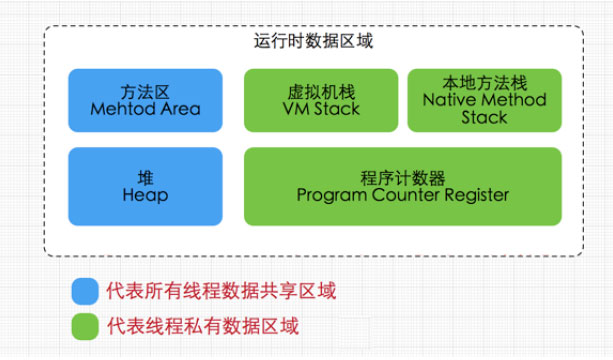
·方法区(Method Area)
方法区属于线程共享的内存区域,又称Non-Heap(非堆),主要用于存储已被虚拟机加载的类信息、常量、静态变量、即时编译器编译后的代码等数据,根据Java 虚拟机规范的规定,当方法区无法满足内存分配需求时,将抛出OutOfMemoryError 异常。值得注意的是在方法区中存在一个叫运行时常量池(Runtime Constant Pool)的区域,它主要用于存放编译器生成的各种字面量和符号引用,这些内容将在类加载后存放到运行时常量池中,以便后续使用。
·JVM堆(Java Heap)
Java 堆也是属于线程共享的内存区域,它在虚拟机启动时创建,是Java 虚拟机所管理的内存中最大的一块,主要用于存放对象实例,几乎所有的对象实例都在这里分配内存,注意Java 堆是垃圾收集器管理的主要区域,因此很多时候也被称做GC 堆,如果在堆中没有内存完成实例分配,并且堆也无法再扩展时,将会抛出OutOfMemoryError异常。
·程序计数器(Program Counter Register)
属于线程私有的数据区域,是一小块内存空间,主要代表当前线程所执行的字节码行号指示器。字节码解释器工作时,通过改变这个计数器的值来选取下一条需要执行的字节码指令,分支、循环、跳转、异常处理、线程恢复等基础功能都需要依赖这个计数器来完成。
·虚拟机栈(Java Virtual Machine Stacks)
属于线程私有的数据区域,与线程同时创建,总数与线程关联,代表Java方法执行的内存模型。每个方法执行时都会创建一个栈桢来存储方法的的变量表、操作数栈、动态链接方法、返回值、返回地址等信息。每个方法从调用直结束就对于一个栈桢在虚拟机栈中的入栈和出栈过程。
·本地方法栈(Native Method Stacks)
本地方法栈属于线程私有的数据区域,这部分主要与虚拟机用到的 Native 方法相关,一般情况下,我们无需关心此区域。
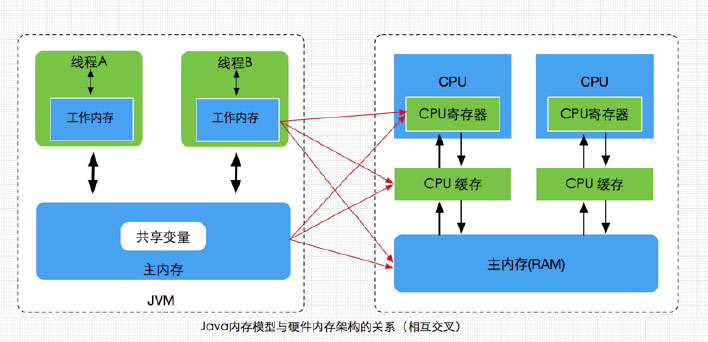
Java内存模型与硬件内存架构的关系
通过对前面的硬件内存架构、Java内存模型以及Java多线程的实现原理的了解,我们应该已经意识到,多线程的执行最终都会映射到硬件处理器上进行执行,但Java内存模型和硬件内存架构并不完全一致。对于硬件内存来说只有寄存器、缓存内存、主内存的概念,并没有工作内存(线程私有数据区域)和主内存(堆内存)之分,也就是说Java内存模型对内存的划分对硬件内存并没有任何影响,因为JMM只是一种抽象的概念,是一组规则,并不实际存在,不管是工作内存的数据还是主内存的数据,对于计算机硬件来说都会存储在计算机主内存中,当然也有可能存储到CPU缓存或者寄存器中,因此总体上来说,Java内存模型和计算机硬件内存架构是一个相互交叉的关系,是一种抽象概念划分与真实物理硬件的交叉。(注意对于Java内存区域划分也是同样的道理)
JMM存在的必要性
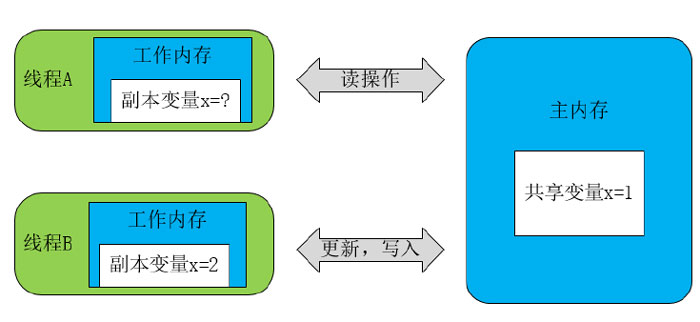
在明白了Java内存区域划分、硬件内存架构、Java多线程的实现原理与Java内存模型的具体关系后,接着来谈谈Java内存模型存在的必要 性。由于JVM运行程序的实体是线程,而每个线程创建时JVM都会为其创建一个工作内存(有些地方称为栈空间),用于存储线程私有的数据,线程与主内存中 的变量操作必须通过工作内存间接完成,主要过程是将变量从主内存拷贝的每个线程各自的工作内存空间,然后对变量进行操作,操作完成后再将变量写回主内存, 如果存在两个线程同时对一个主内存中的实例对象的变量进行操作就有可能诱发线程安全问题。
如下图,主内存中存在一个共享变量x,现在有A和B两条线程分别对该变量x=1进行操作,A/B线程各自的工作内存中存在共享变量副本x。假设现在A线程想要修改x的值为2,而B线程却想要读取x的值,那么B线程读取 到的值是A线程更新后的值2还是更新前的值1呢?答案是,不确定,即B线程有可能读取到A线程更新前的值1,也有可能读取到A线程更新后的值2,这是因为 工作内存是每个线程私有的数据区域,而线程A变量x时,首先是将变量从主内存拷贝到A线程的工作内存中,然后对变量进行操作,操作完成后再将变量x写回主 内,而对于B线程的也是类似的,这样就有可能造成主内存与工作内存间数据存在一致性问题,假如A线程修改完后正在将数据写回主内存,而B线程此时正在读取 主内存,即将x=1拷贝到自己的工作内存中,这样B线程读取到的值就是x=1,但如果A线程已将x=2写回主内存后,B线程才开始读取的话,那么此时B线 程读取到的就是x=2,但到底是哪种情况先发生呢?这是不确定的,这也就是所谓的线程安全问题。
为了解决类似上述的问题,JVM定义了一组规则,通过这组规则来决定一个线程对共享变量的写入何时对另一个线程可见,这组规则也称为Java内存模型(即JMM),JMM是围绕着程序执行的原子性、有序性、可见性展开的,下面我们看看这三个特性。
内存间交互操作
关于主内存与工作内存之间具体的交互协议,即一个变量如何从主内存拷贝到工作内 存、如何从工作内存同步回主内存之类的实现细节,Java内存模型中定义了以下8种操作来完成,虚拟机实现时必须保证下面提及的每一种操作都是原子的、不可再分的。lock(锁定):作用于主内存的变量,它把一个变量标识为一条线程独占的状态。
unlock(解锁):作用于主内存的变量,它把一个处于锁定状态的变量释放出来,释放后的变量才可以被其他线程锁定。
read(读取):作用于主内存的变量,它把一个变量的值从主内存传输到线程的工作内存中,以便随后的load动作使用。
load(载入):作用于工作内存的变量,它把read操作从主内存中得到的变量值放入工作内存的变量副本中。
use(使用):作用于工作内存的变量,它把工作内存中一个变量的值传递给执行引擎,每当虚拟机遇到一个需要使用到变量的值的字节码指令时将会执行这个操作。
assign(赋值):作用于工作内存的变量,它把一个从执行引擎接收到的值赋给工作内存的变量,每当虚拟机遇到一个给变量赋值的字节码指令时执行这个操作。
store(存储):作用于工作内存的变量,它把工作内存中一个变量的值传送到主内存中,以便随后的write操作使用。
write(写入):作用于主内存的变量,它把store操作从工作内存中得到的变量的值放入主内存的变量中。
如果要把一个变量从主内存复制到工作内存,那就要顺序地执行read和load操作,如果要把变量从工作内存同步回主内存,就要顺序地执行store和write操作。注意,Java内存模型只要求上述两个操作必须按顺序执行,而没有保证是连续执行。也就是说,read与load之间、store与write之间是可插入其他指令的,如对主内存中的变量a、b进行访问时,一种可能出现顺序是read a、read b、load b、load a。除此之外,Java内存模型还规定了在执行上述8种基本操作时必须满足如下规则:
·不允许read和load、store和write操作之一单独出现,即不允许一个变量从主内存读取了但工作内存不接受,或者从工作内存发起回写了但主内存不接受的情况出现。
·不允许一个线程丢弃它的最近的assign操作,即变量在工作内存中改变了之后必须把该变化同步回主内存。
·不允许一个线程无原因地(没有发生过任何assign操作)把数据从线程的工作内存同步回主内存中。
·一个新的变量只能在主内存中“诞生”,不允许在工作内存中直接使用一个未被初始化(load或assign)的变量,换句话说,就是对一个变量实施use、store操作之前,必须先执行过了assign和load操作。
·一个变量在同一个时刻只允许一条线程对其进行lock操作,但lock操作可以被同一条线程重复执行多次,多次执行lock后,只有执行相同次数的unlock操作,变量才会被解锁。
·如果对一个变量执行lock操作,那将会清空工作内存中此变量的值,在执行引擎使用这个变量前,需要重新执行load或assign操作初始化变量的值
·如果一个变量事先没有被lock操作锁定,那就不允许对它执行unlock操作,也不允许去unlock一个被其他线程锁定住的变量。
·对一个变量执行unlock操作之前,必须先把此变量同步回主内存中(执行store、write操作)。
这8种内存访问操作以及上述规则限定,再加上稍后介绍的对volatile的一些特殊规定,就已经完全确定了Java程序中哪些内存访问操作在并发下是安全的。由于这种定义相当严谨但又十分烦琐,实践起来很麻烦,所以在12.3.6节中笔者将介绍这种定义的一个等效判断原则——先行发生原则,用来确定一个访问在并发环境下是否安全。
原子性、可见性与有序性
原子性
原子性指的是一个操作是不可中断的,即使是在多线程环境下,一个操作一旦开始就不会被其他线程影响。由Java内存模型来直接保证的原子性变量操作包括read、load、assign、use、store和write,我们大致可以认为基本数据类型的访问读写是具备原子性的,但是对于64位的数据类型(long和double),在模型中特别定义了一条相对宽松的规定:允许虚拟机将没有被volatile修饰的64位数据的读写操作划分为两次32位的操作来进行,这样会导致一个线程在写时,操作完前32位的原子操作后,轮到B线程读取时,恰好只读取到了后32位的数据,这样可能会读取到一个既非原值又不是线程修改值的变量,它可能是“半个变量”的数值,即64位数据被两个线程分成了两次读取。但也不必太担心,因为读取到“半个变量”的情况比较少 见,至少在目前的商用的虚拟机中,几乎都把64位的数据的读写操作作为原子操作来执行,因此对于这个问题不必太在意,知道这么回事即可。
如果应用场景需要一个更大范围的原子性保证(经常会遇到),Java内存模型还提供了lock和unlock操作来满足这种需求,尽管虚拟机未把lock和unlock操作直接开放给用户使用,但是却提供了更高层次的字节码指令monitorenter和monitorexit来隐式地使用这两个操作,这两个字节码指令反映到Java代码中就是同步块——synchronized关键字,因此在synchronized块之间的操作也具备原子性。
可见性
可见性是指当一个线程修改了共享变量的值,其他线程能够立即得知这个修改。对于串行程序来说,可见性问题是不存在的,因为我们在任何一个操作中修改了某个变量的值,后续的操作中都能读取这个变量值,并且是修改过的新值。但在多线程环境中可就不一定了, 前面我们分析过,由于线程对共享变量的操作都是线程拷贝到各自的工作内存进行操作后才写回到主内存中的,这就可能存在一个线程A修改了共享变量x的值,还未写回主内存时,另外一个线程B又对主内存中同一个共享变量x进行操作,但此时A线程工作内存中共享变量x对线程B来说并不可见,这种工作内存与主内存同步延迟现象就会造成可见性问题。
有序性
有序性是指对于单线程的执行代码,我们总是认为代码的执行是按顺序依次执行的,这样的理解并没有毛病,毕竟对于单线程而言确实如此,但对于多线程环境,则可能出现乱序现象,因为程序编译成机器码指令后可能会出现指令重排现象,重排后的指令与原指令的顺序未必一致,要明白的是,在Java程序中,倘若在本线程内,所有操作都视为有序行为,如果是多线程环境下,一个线程中观察另外一个线程,所有操作都是无序的,前半句指的是单线程内保证串行语义执行的一 致性,后半句则指指令重排现象和工作内存与主内存同步延迟现象。
JMM提供的解决方案
在理解了原子性,可见性以及有序性问题后,看看JMM是如何保证的,在Java内存模型中都提供一套解决方案供Java工程师在开发过程使用,如原子性问题,除了JVM自身提供的对基本数据类型读写操作的原子性外,对于方法级别或者代码块级别的原子性操作,可以使用synchronized关键字或 者重入锁(ReentrantLock)保证程序执行的原子性。 而工作内存与主内存同步延迟现象导致的可见性问题,可以使用synchronized关键字或者volatile关键字解决,它们都可以使一个线程修改后 的变量立即对其他线程可见。对于指令重排导致的可见性问题和有序性问题,则可以利用volatile关键字解决,因为volatile的另外一个作用就是 禁止重排序优化,关于volatile稍后会进一步分析。除了靠sychronized和volatile关键字来保证原子性、可见性以及有序性外,JMM内部还定义一套happens-before原则来保证多线程环境下两个操作间的原子性、可见性以及有序性。推荐了解传智播客java培训课程。
volatile内存语义
volatile是Java虚拟机提供的轻量级的同步机制。volatile关键字有如下三个作用:
·在工作内存中,每次使用volatile修饰的变量前都必须先从主内存刷新最新的值,用于保证能看见其他线程对volatile修饰的变量所做的修改后的值
·要求在工作内存中,每次修改volatile修饰的变量后都必须立刻同步回主内存中,用于保证其他线程可以看到自己对volatile修饰的变量所做的修改
·要求volatile修饰的变量不会被指令重排序优化,保证代码的执行顺序与程序的顺序相同
先行发生原则
倘若在程序开发中,仅靠sychronized和volatile关键字来保证原子性、可见性以及有序性,那么编写并发程序可能会显得十分麻烦,幸 运的是,在Java内存模型中,还提供了happens-before 原则来辅助保证程序执行的原子性、可见性以及有序性的问题,它是判断数据是否存在竞争、线程是否安全的依据,happens-before 原则内容如下
程序顺序原则,即在一个线程内必须保证语义串行性,也就是说按照代码顺序执行。
(1)锁规则:解锁(unlock)操作必然发生在后续的同一个锁的加锁(lock)之前,也就是说,如果对于一个锁解锁后,再加锁,那么加锁的动作必须在解锁动作之后(同一个锁)。
(2)volatile规则:volatile变量的写,先发生于读,这保证了volatile变量的可见性,简单的理解就是,volatile变量在每次被线程访问时,都强迫从主内 存中读该变量的值,而当该变量发生变化时,又会强迫将最新
的值刷新到主内存,任何时刻,不同的线程总是能够看到该变量的最新值。
(3)线程启动规则:线程的start()方法先于它的每一个动作,即如果线程A在执行线程B的start方法之前修改了共享变量的值,那么当线程B执行start方法时,线程A对共享变量的修改对线程B可见
(4)传递性:A先于B ,B先于C 那么A必然先于C
(5)线程终止规则 线程的所有操作先于线程的终结,Thread.join()方法的作用是等待当前执行的线程终止。
(6)在线程B终止之前,修改了共享变量,线程A从线程B的join方法成功返回后,线程B对共享变量的修改将对线程A可见。
(7)线程中断规则:对线程 interrupt()方法的调用先行发生于被中断线程的代码检测到中断事件的发生,可以通过Thread.interrupted()方法检测线程是否中断。
(8)对象终结规则:对象的构造函数执行,结束先于finalize()方法
上述8条原则无需手动添加任何同步手段(synchronized|volatile)即可达到效果,下面我们结合前面的案例演示这8条原则如何判断线程是否安全,如下:
class MixedOrder{
同样的道理,存在两条线程A和B,线程A调用实例对象的writer()方法,而线程B调用实例对象的read()方法,线程A先启动而线程B后启动,那么线程B读取到的i值是多少呢?现在依据8条原则,由于存在两条线程同时调用,因此程序次序原则不合适。writer()方法和read()方法都没有使用同步手段,锁规则也不合适。没有使用volatile关键字,volatile变量原则不适应。线程启动规则、线程终止规则、线程中断规则、对象结规则、传递性和本次测试案例也不合适。线程A和线程B的启动时间虽然有先后,但线程B执行结果却是不确定,也是说上述代码没有适合8条原则中的任意一,也没有使用任何同步手段,所以上述的操作是线程不安全的,因此线程B读取的值自然也是不确定的。修复这个问题的方式很简单,要么给writer()方 法和read()方法添加同步手段,如synchronized或者给变量flag添加volatile关键字,确保线程A修改的值对线程B总是可见。
时间先后顺序与先行发生原则之间基本没有太大的关系,所以我们衡量并发安全问题的时候不要受到时间顺序的干扰,一切必须以先行发生原则为准。
猜你喜欢:
最新资讯




















江苏传智播客教育科技股份有限公司 版权所有Copyright 2006-2024 All
Rights Reserved
苏ICP备16007882号营业执照增值电信业务经营许可证出版物经营许可证 苏公网安备 32132202001156号
苏公网安备 32132202001156号
免费领取黑马程序员AI通道专属星级课程资料
