











 AI智能应用开发
AI智能应用开发 AI大模型开发(Python)
AI大模型开发(Python) AI鸿蒙开发
AI鸿蒙开发 AI嵌入式+机器人开发
AI嵌入式+机器人开发 AI运维
AI运维 AI测试
AI测试 跨境电商运营
跨境电商运营 AI设计
AI设计 AI视频创作与直播运营
AI视频创作与直播运营 微短剧拍摄剪辑
微短剧拍摄剪辑 C/C++
C/C++ 狂野架构师
狂野架构师


filter的执行顺序是怎样的?
更新时间:2020年07月08日15时43分 来源:传智播客 浏览次数:
1.引言
我们在编写javaweb程序的时候,时常会用filter这个组件,它能将我们一些通用逻辑抽取出来,在servlet执行业务逻辑之前运行,
达到简化代码和复用的目的.比如最常用的场景全站编码和登录验证功能。
servlet3.0以前我们只能通过web.xml的方式配置filter,并且多个filter的执行顺序是根据你web.xml中书写顺序来决定的.
servlet3.0以后,提供了注解的方式注入filter,只需要在filter类上加上@WebFilter()注解即可,大大的简化了开发复杂度.
2.抛出问题
注解的方式书写的filter的执行顺序又是如何的呢?
网上的很多资料都说是根据filter的类名来决定,也有说是根据filter的注解的name属性值的字母顺序来决定的.
对不对呢?
2.验证问题
我们创建了三个filter 来验证此问题
filter1号
package com.jk1123.web.filter.demo01;import javax.servlet.*;
import javax.servlet.annotation.WebFilter;
import java.io.IOException;
@WebFilter("/*")
public class OrderFilter1 implements Filter {
public void destroy() {
}
public void doFilter(ServletRequest req, ServletResponse resp, FilterChain chain) throws ServletException, IOException {
System.out.println("orderFilter1执行了..");
chain.doFilter(req, resp);
}
public void init(FilterConfig config) throws ServletException {
}
}
filter2号
package com.jk1123.web.filter.demo02;import javax.servlet.*;
import javax.servlet.annotation.WebFilter;
import java.io.IOException;
@WebFilter("/*")
public class OrderFilter2 implements Filter {
public void destroy() {
}
public void doFilter(ServletRequest req, ServletResponse resp, FilterChain chain) throws ServletException, IOException {
System.out.println("orderFilter2执行了..");
//这是放行
chain.doFilter(req, resp);
}
public void init(FilterConfig config) throws ServletException {
}
}
filter3号
package com.jk1123.web.filter.demo03;import javax.servlet.*;
import javax.servlet.annotation.WebFilter;
import java.io.IOException;
@WebFilter("/*")
public class OrderFilter3 implements Filter {
public void destroy() {
}
public void doFilter(ServletRequest req, ServletResponse resp, FilterChain chain) throws ServletException, IOException {
System.out.println("orderFilter3执行了..");
//这是放行
chain.doFilter(req, resp);
}
public void init(FilterConfig config) throws ServletException {
}
}
配上一个servlet 来访问试试
package com.jk1123.web.servlet;import javax.servlet.ServletException;
import javax.servlet.annotation.WebServlet;
import javax.servlet.http.HttpServlet;
import javax.servlet.http.HttpServletRequest;
import javax.servlet.http.HttpServletResponse;
import java.io.IOException;
@WebServlet("/foo")
public class FooServlet extends HttpServlet {
protected void doPost(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException {
this.doGet(request, response);
}
protected void doGet(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException {
response.getWriter().print("foo servlet");
}
}
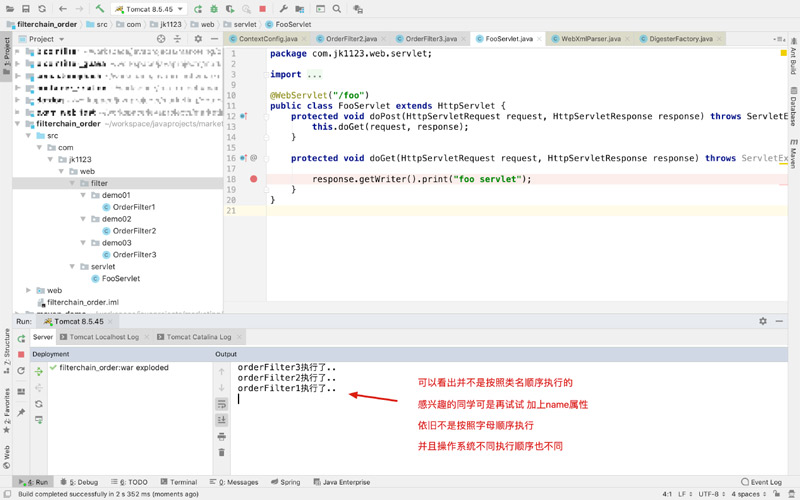
验证结果:
3.查看源码
可以从上面验证看出 好像并不是根据类名或者filter的name属性的字母排序执行,那到底是根据什么执行的呢?
点开源码,我们一点点探寻它的秘密。
需要搞清楚如下问题
1.filterChain是什么时候执行的呢?
2.filterChain中的filter来源何处?
3.standardContext什么时候开始收集的过滤器集合
我们先查询第一段源码 解密filterChain是什么时候执行的

//在org.apache.catalina.core.StandardWrapperValve 类中有如下一个方法
public final void invoke(Request request, Response response)
throws IOException, ServletException {
//省略掉大段无关代码
//0.生命servlet对象
Servlet servlet = null;
/**
* 省略一大段无关代码
*/
try {
if (!unavailable) {
//1.这里创建正在访问的servlet对象
servlet = wrapper.allocate();
}
} catch (UnavailableException e) {
//省略掉大段无关代码
}
//省略大段无关代码
//2.创建过滤器链对象
ApplicationFilterChain filterChain =
ApplicationFilterFactory.createFilterChain(request, wrapper, servlet);
try {
if ((servlet != null) && (filterChain != null)) {
// Swallow output if needed
if (context.getSwallowOutput()) {
//省略掉大段无关代码
} else {
if (request.isAsyncDispatching()) {
request.getAsyncContextInternal().doInternalDispatch();
} else {
//3.执行过滤链对象doFilter方法
filterChain.doFilter
(request.getRequest(), response.getResponse());
}
}
}
} catch (ClientAbortException | CloseNowException e) {
//省略掉大段无关代码
}
}
我们一会儿回过头来看它是如何创建过滤器链对象的代码,我们先来看他是如何执行过滤器链的,
过滤器链对象的实现为:
package org.apache.catalina.core;
//我们只保留 跟执行序列有关的代码
public final class ApplicationFilterChain implements FilterChain {
//当前正在执行的filter索引
private int pos = 0;
//总共有多少个filter匹配上了
private int n = 0;
//关联的要执行的servlet对象
private Servlet servlet = null;
//匹配上的filter数组
private ApplicationFilterConfig[] filters = new ApplicationFilterConfig[0];
@Override
public void doFilter(ServletRequest request, ServletResponse response)
throws IOException, ServletException {
if( Globals.IS_SECURITY_ENABLED ) {
//删除无关代码
} else {
//0.执行内容的doFilter方法
internalDoFilter(request,response);
}
}
private void internalDoFilter(ServletRequest request,
ServletResponse response)
throws IOException, ServletException {
// Call the next filter if there is one
if (pos < n) {
//这个地方主义有个pos++ 进来一次 ++一次
ApplicationFilterConfig filterConfig = filters[pos++];
try {
Filter filter = filterConfig.getFilter();
//删除大段无关代码
if( Globals.IS_SECURITY_ENABLED ) {
//删除大段无关代码
} else {
//执行过滤器链中的过滤器的doFilter方法
//而我们的过滤器中满足条件后 放行 放行就会跳转回来执行过滤器链的
//的doFilter 也就是又回来执行第二个
filter.doFilter(request, response, this);
}
} catch (IOException | ServletException | RuntimeException e) {
throw e;
} catch (Throwable e) {
e = ExceptionUtils.unwrapInvocationTargetException(e);
ExceptionUtils.handleThrowable(e);
throw new ServletException(sm.getString("filterChain.filter"), e);
}
return;
}
try {
//删除大段无关代码
// Use potentially wrapped request from this point
if ((request instanceof HttpServletRequest) &&
(response instanceof HttpServletResponse) &&
Globals.IS_SECURITY_ENABLED ) {
//删除大段无关代码
} else {
//如果没有需要执行的filter就会执行 servlet的service方法 也就是我们写的业务逻辑
servlet.service(request, response);
}
} catch (IOException | ServletException | RuntimeException e) {
throw e;
} catch (Throwable e) {
e = ExceptionUtils.unwrapInvocationTargetException(e);
ExceptionUtils.handleThrowable(e);
throw new ServletException(sm.getString("filterChain.servlet"), e);
} finally {
if (ApplicationDispatcher.WRAP_SAME_OBJECT) {
lastServicedRequest.set(null);
lastServicedResponse.set(null);
}
}
}
}
从filterChain类的源码可以看出底层是包含了 所匹配上的filter数组 也就是添加进去匹配上过滤器对象是有序的 添加的时候就决定了!!!
那么它是什么时候添加的呢?
2.filterChain中的filter来源何处?
其实我们在在org.apache.catalina.core.StandardWrapperValve 类的invoke方法中
ApplicationFilterChain filterChain =ApplicationFilterFactory.createFilterChain(request, wrapper, servlet);
点开这段代码查询把!
public static ApplicationFilterChain createFilterChain(ServletRequest request,
Wrapper wrapper, Servlet servlet) {
// If there is no servlet to execute, return null
if (servlet == null)
return null;
// 在这里创建ApplicationFilterChain 对象
//但是对象里还没有filter对象
ApplicationFilterChain filterChain = null;
if (request instanceof Request) {
Request req = (Request) request;
if (Globals.IS_SECURITY_ENABLED) {
// Security: Do not recycle
filterChain = new ApplicationFilterChain();
} else {
filterChain = (ApplicationFilterChain) req.getFilterChain();
if (filterChain == null) {
filterChain = new ApplicationFilterChain();
req.setFilterChain(filterChain);
}
}
} else {
// Request dispatcher in use
filterChain = new ApplicationFilterChain();
}
filterChain.setServlet(servlet);
filterChain.setServletSupportsAsync(wrapper.isAsyncSupported());
// Acquire the filter mappings for this Context
StandardContext context = (StandardContext) wrapper.getParent();
//获取ServletContext对象 注册的所有的filter数组
FilterMap filterMaps[] = context.findFilterMaps();
// If there are no filter mappings, we are done
if ((filterMaps == null) || (filterMaps.length == 0))
return filterChain;
// Acquire the information we will need to match filter mappings
DispatcherType dispatcher =
(DispatcherType) request.getAttribute(Globals.DISPATCHER_TYPE_ATTR);
String requestPath = null;
Object attribute = request.getAttribute(Globals.DISPATCHER_REQUEST_PATH_ATTR);
if (attribute != null){
requestPath = attribute.toString();
}
String servletName = wrapper.getName();
//这里开始遍历 filterMaps数组根据请求路径匹配添加
for (int i = 0; i < filterMaps.length; i++) {
if (!matchDispatcher(filterMaps[i] ,dispatcher)) {
continue;
}
if (!matchFiltersURL(filterMaps[i], requestPath))
continue;
ApplicationFilterConfig filterConfig = (ApplicationFilterConfig)
context.findFilterConfig(filterMaps[i].getFilterName());
if (filterConfig == null) {
// FIXME - log configuration problem
continue;
}
filterChain.addFilter(filterConfig);
}
// Add filters that match on servlet name second
for (int i = 0; i < filterMaps.length; i++) {
if (!matchDispatcher(filterMaps[i] ,dispatcher)) {
continue;
}
if (!matchFiltersServlet(filterMaps[i], servletName))
continue;
ApplicationFilterConfig filterConfig = (ApplicationFilterConfig)
context.findFilterConfig(filterMaps[i].getFilterName());
if (filterConfig == null) {
// FIXME - log configuration problem
continue;
}
filterChain.addFilter(filterConfig);
}
// Return the completed filter chain
return filterChain;
}
可以看出在创建filterChain对象时候,从ServletContext获取所有注册的filter的数组 取出需要的添加到这次请求创建的filterChain对象中
而且servletContext对象的注册的所有的过滤器本身就是一个数组 本身就是有序的,所以遍历匹配的时候,也就是有序的!
3、ServletContext什么时候开始收集的数组,从哪来的呢?
这个要从tomcat启动的时候来看了!
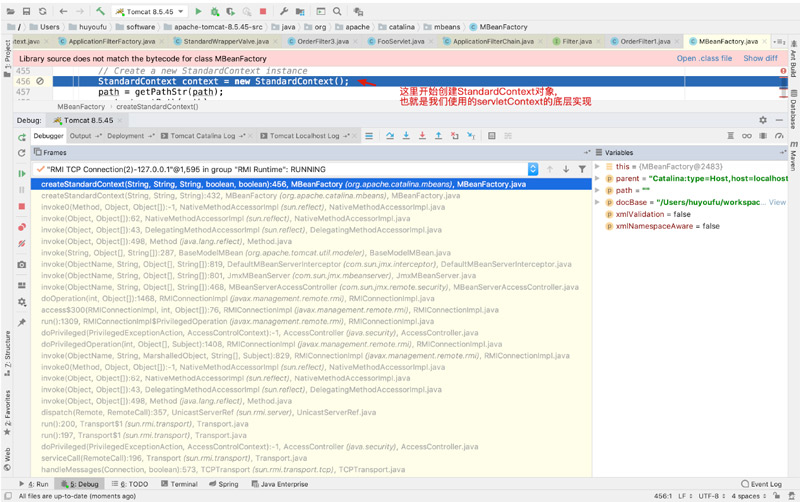
而StandardContext创建完成以后就要开始初始化操作了!
StandardContext.startInternal()方法---->fireLifecycleEvent()方法-->ContextConfig.lifecycleEvent()-->ContextConfig.lifecycleEventcon-->ContextConfig.con.figureStart()-->ContextConfig.webConfig()
好了我们现在查看该方法:
protected void webConfig() {WebXmlParser webXmlParser = new WebXmlParser(context.getXmlNamespaceAware(),
context.getXmlValidation(), context.getXmlBlockExternal());
Set<WebXml> defaults = new HashSet<>();
defaults.add(getDefaultWebXmlFragment(webXmlParser));
//创建了web.xml 配置文件对象
//也就是它就代表我们项目的配置相关的信息
WebXml webXml = createWebXml();
// Parse context level web.xml
InputSource contextWebXml = getContextWebXmlSource();
//解析web.xml 配置文件
//发现配置文件中的 filter servlet listener等配置
//而xml的解析是从上到下 所以你在web.xml 配置filter
//得到filter集合就是有序的
if (!webXmlParser.parseWebXml(contextWebXml, webXml, false)) {
ok = false;
}
ServletContext sContext = context.getServletContext();
//省略大段无关代码
if (!webXml.isMetadataComplete() || typeInitializerMap.size() > 0) {
// Steps 4 & 5.
//扫描编译的类文件 寻找注解方式书写的servlet filter listener
processClasses(webXml, orderedFragments);
}
//省略大段无关代码
}
从上面代码 可以看出web,xml配置的filter肯定是有序的了 解析的时候 就会收集到webXml对象的
//采用的是linkedHashset来存储的 是有序的private final Set<FilterMap> filterMaps = new LinkedHashSet<>();
解析xml过程我们就不看了 人家才是的digester的xml解析框架来做.
我们来查看processClasses(webXml, orderedFragments); 这个方法是解析注解用的
protected void processClasses(WebXml webXml, Set<WebXml> orderedFragments) {// Step 4. Process /WEB-INF/classes for annotations and
// @HandlesTypes matches
Map<String, JavaClassCacheEntry> javaClassCache = new HashMap<>();
if (ok) {
//获取项目下的类路径
WebResource[] webResources =
context.getResources().listResources("/WEB-INF/classes");
for (WebResource webResource : webResources) {
// Skip the META-INF directory from any JARs that have been
// expanded in to WEB-INF/classes (sometimes IDEs do this).
if ("META-INF".equals(webResource.getName())) {
continue;
}
//开始根据注解解析了
processAnnotationsWebResource(webResource, webXml,
webXml.isMetadataComplete(), javaClassCache);
}
}
// Step 5. Process JARs for annotations and
// @HandlesTypes matches - only need to process those fragments we
// are going to use (remember orderedFragments includes any
// container fragments)
if (ok) {
processAnnotations(
orderedFragments, webXml.isMetadataComplete(), javaClassCache);
}
// Cache, if used, is no longer required so clear it
javaClassCache.clear();
}
查看processAnnotationsWebResource方法
protected void processAnnotationsWebResource(WebResource webResource,WebXml fragment, boolean handlesTypesOnly,
Map<String,JavaClassCacheEntry> javaClassCache) {
//看看是否是个目录
if (webResource.isDirectory()) {
WebResource[] webResources =
webResource.getWebResourceRoot().listResources(
webResource.getWebappPath());
if (webResources.length > 0) {
if (log.isDebugEnabled()) {
log.debug(sm.getString(
"contextConfig.processAnnotationsWebDir.debug",
webResource.getURL()));
}
//遍历目录
for (WebResource r : webResources) {
//递归处理
processAnnotationsWebResource(r, fragment, handlesTypesOnly, javaClassCache);
}
}
} else if (webResource.isFile() &&
webResource.getName().endsWith(".class")) {
try (InputStream is = webResource.getInputStream()) {
//如果是类文件的话 开始处理
processAnnotationsStream(is, fragment, handlesTypesOnly, javaClassCache);
} catch (IOException e) {
log.error(sm.getString("contextConfig.inputStreamWebResource",
webResource.getWebappPath()),e);
} catch (ClassFormatException e) {
log.error(sm.getString("contextConfig.inputStreamWebResource",
webResource.getWebappPath()),e);
}
}
}
查看processAnnotationsStream方法
protected void processAnnotationsStream(InputStream is, WebXml fragment,boolean handlesTypesOnly, Map<String,JavaClassCacheEntry> javaClassCache)
throws ClassFormatException, IOException {
ClassParser parser = new ClassParser(is);
JavaClass clazz = parser.parse();
checkHandlesTypes(clazz, javaClassCache);
if (handlesTypesOnly) {
return;
}
//处理开始
processClass(fragment, clazz);
}
protected void processClass(WebXml fragment, JavaClass clazz) {
AnnotationEntry[] annotationsEntries = clazz.getAnnotationEntries();
if (annotationsEntries != null) {
String className = clazz.getClassName();
for (AnnotationEntry ae : annotationsEntries) {
String type = ae.getAnnotationType();
if ("Ljavax/servlet/annotation/WebServlet;".equals(type)) {
processAnnotationWebServlet(className, ae, fragment);
//判断是否webFilter注解 如果是就添加到 webxml配置对象中
}else if ("Ljavax/servlet/annotation/WebFilter;".equals(type)) {
processAnnotationWebFilter(className, ae, fragment);
}else if ("Ljavax/servlet/annotation/WebListener;".equals(type)) {
fragment.addListener(className);
} else {
// Unknown annotation - ignore
}
}
}
}
从上面可以看出原来扫描类路径的时候,就是先遍历文件夹 遍历文件夹下类文件 反射查看是否是一个带有WebFilter注解的类
如果是就添加到web.xml中set集合中,而那个set集合是有序的linkedset
所有顺序就是递归遍历文件夹的顺序 一切就看 递归的时候如何获取下级文件夹的代码了 看它是否进行排序了?
也就是说由如下代码决定的
WebResource[] webResources =webResource.getWebResourceRoot().listResources(
webResource.getWebappPath());
点开这段代码
protected WebResource[] listResources(String path, boolean validate) {if (validate) {
path = validate(path);
}
String[] resources = list(path, false);
WebResource[] result = new WebResource[resources.length];
for (int i = 0; i < resources.length; i++) {
if (path.charAt(path.length() - 1) == '/') {
result[i] = getResource(path + resources[i], false, false);
} else {
result[i] = getResource(path + '/' + resources[i], false, false);
}
}
return result;
}
//继续
private String[] list(String path, boolean validate) {
if (validate) {
path = validate(path);
}
// Set because we don't want duplicates
// LinkedHashSet to retain the order. It is the order of the
// WebResourceSet that matters but it is simpler to retain the order
// over all of the JARs.
HashSet<String> result = new LinkedHashSet<>();
for (List<WebResourceSet> list : allResources) {
for (WebResourceSet webResourceSet : list) {
if (!webResourceSet.getClassLoaderOnly()) {
String[] entries = webResourceSet.list(path);
for (String entry : entries) {
result.add(entry);
}
}
}
}
return result.toArray(new String[result.size()]);
}
//继续
public String[] list(String path) {
checkPath(path);
String webAppMount = getWebAppMount();
if (path.startsWith(webAppMount)) {
File f = file(path.substring(webAppMount.length()), true);
if (f == null) {
return EMPTY_STRING_ARRAY;
}
//就到这里了 我们可以看到 它没有排序就是调用了
//file类的list方法
String[] result = f.list();
if (result == null) {
return EMPTY_STRING_ARRAY;
} else {
return result;
}
} else {
if (!path.endsWith("/")) {
path = path + "/";
}
if (webAppMount.startsWith(path)) {
int i = webAppMount.indexOf('/', path.length());
if (i == -1) {
return new String[] {webAppMount.substring(path.length())};
} else {
return new String[] {
webAppMount.substring(path.length(), i)};
}
}
return EMPTY_STRING_ARRAY;
}
}
来来打开file类的list方法看看
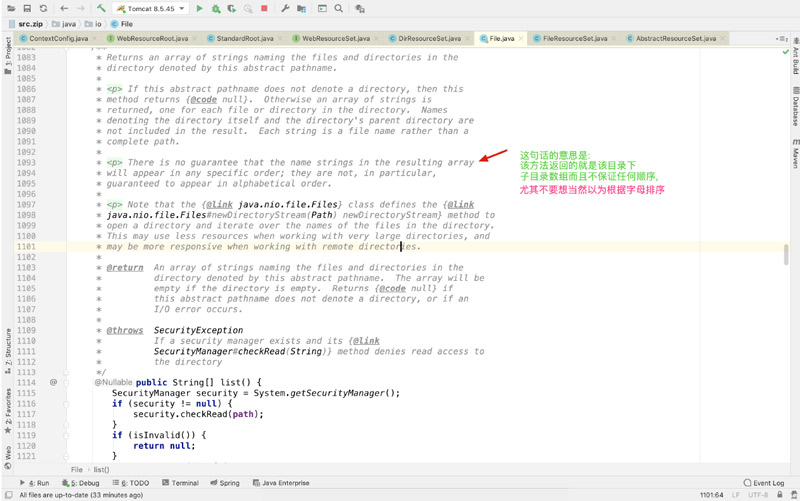
所以最终 web.xml收集到所有filter的set集合 如果采用的是注解方式 没有任何顺序可言的.
然后接下来的代码我们就不看了无非就是将收集到的filter集合转换成数组 设置给StandardContext对象
4.得出结论
如果采用web.xml写的filter执行顺序跟书写顺序有关
而采用注解方式的是没有顺序可言的!!!!
而采用注解方式的是没有顺序可言的!!!!
而采用注解方式的是没有顺序可言的!!!!
实践出真知!切记人云亦云!有问题找源码!!!
猜你喜欢:
Java中级程序员培训课程
最新资讯




















江苏传智播客教育科技股份有限公司 版权所有Copyright 2006-2024 All
Rights Reserved
苏ICP备16007882号营业执照增值电信业务经营许可证出版物经营许可证 苏公网安备 32132202001156号
苏公网安备 32132202001156号
免费领取黑马程序员AI通道专属星级课程资料
